We started this series off with a deep dive into the most famous statistical models used for time series forecasting, and how well they perform. (Read Part 1 here.) We saw that while the results were good enough for short term forecasts, any slight increase in our forecasting horizon caused not only a decrease in performance, but an increase in training time. Above all, these models were not easy to tune. Along with a good understanding of the data, one would also need significant statistical background to optimize the results produced by the likes of ARIMA, SARIMA, SARIMAX or Prophet.
In this second part, we’ll look at two of the most commonly-used machine and deep learning algorithms for time series forecasting: LSTMs and LightGBM. We won’t do any exploratory data analysis, this was done in part one, so I will refer you to that article if you’re interested in seeing what the BikeShare Demand time series we’re using looks like.
Note: The entire notebook, with all the code, can be found in this public repository.
Analysis setup
Computing environment
All models will be trained and tested on a machine with 128 GB of memory and 32 cores, in a Databricks environment.
Forecasting
We'll start by looking at a widely used machine learning algorithm, not only for time series, but for any tabular data in general: LightGBM. LightGBM is a gradient boosting framework that uses tree-based learning algorithms. It is designed to be distributed and efficient, with the advantage of being fast, scalable, and accurate. We'll use the LGBMRegressor class to forecast, but before doing so, we need to preprocess our data in a way that it's understood by LightGBM. Namely, we'll:
1. Convert our data so that it can be viewed as a supervised learning problem. This is done by adding columns for observations at time t-1, t-2, ..., t-4, and use these observations to predict demand at time t. Note that we could've looked further into the past e.g., t-10, but chose to stick with four time periods.
2. We standardize the data, as is assumed by LGBM.

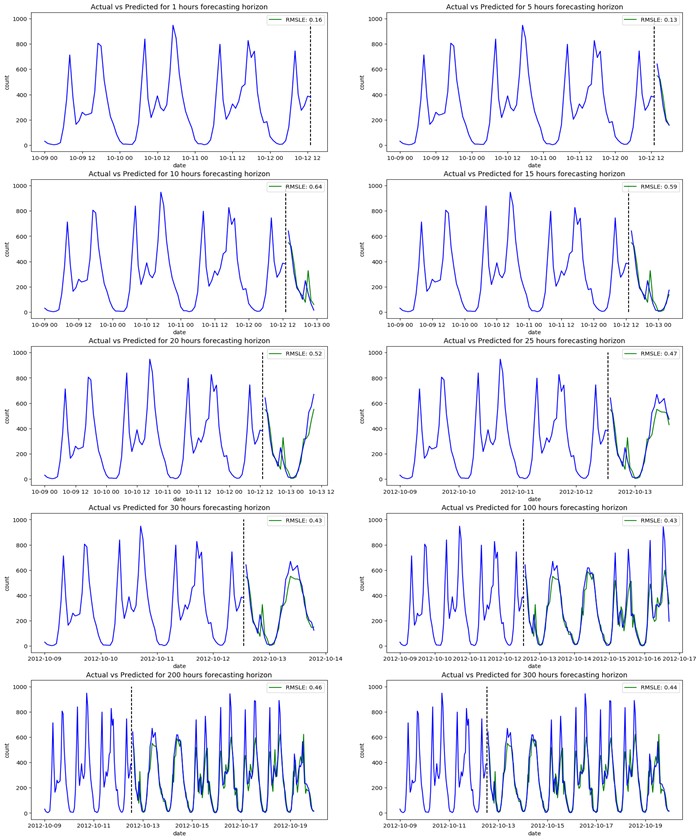
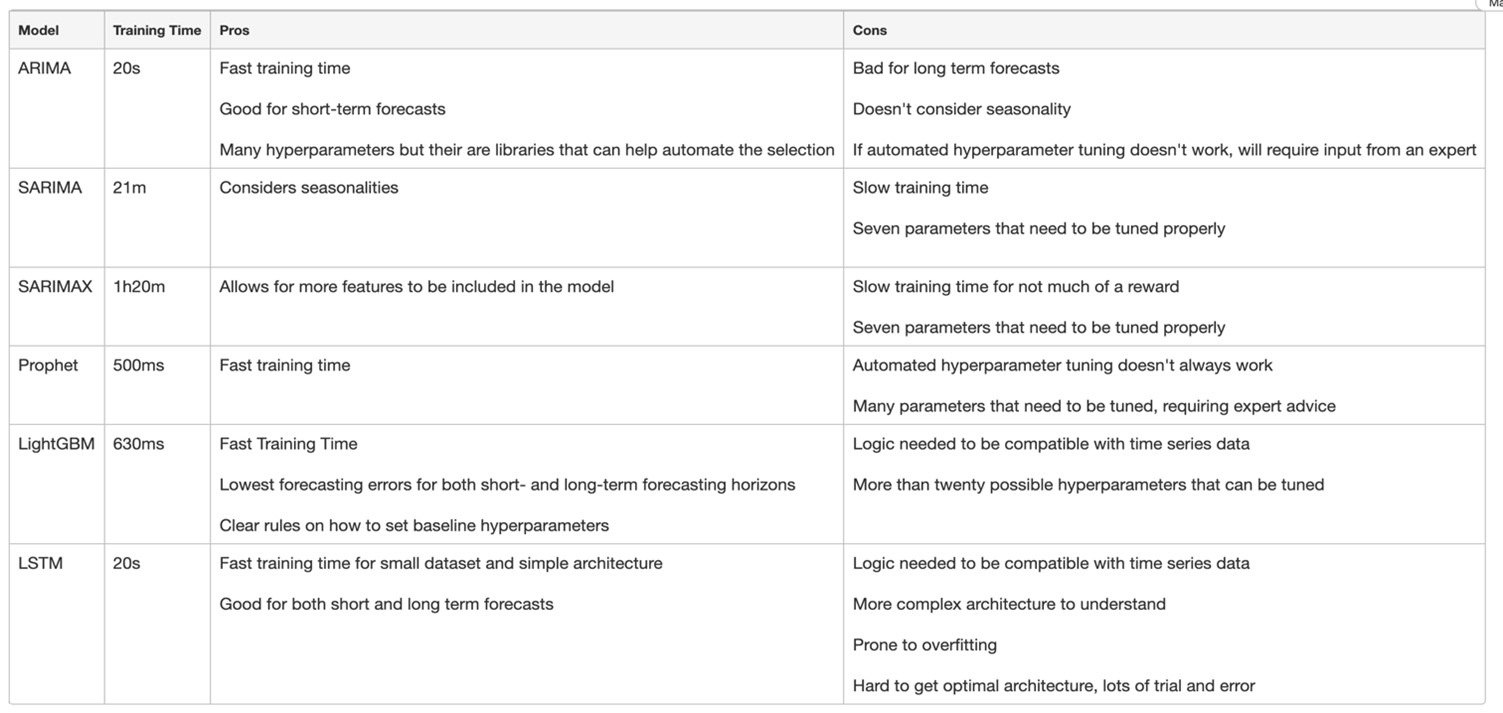
Very interesting results. Not only is the training time extremely low, but the RMSLE is also low for both short- and long-term forecasting. Of course, an error of 0.44 for a forecasting horizon of 300 hours isn’t great, but when compared to previous models, LGBM is well ahead. As for the number of hyperparameters, LightGBM has over 20 possible parameters that can be included.
The ones we chose are claimed by LGBM’s documentation to be the most important. Selecting these parameters wasn’t difficult; we simply followed the suggestions in the documentation as to how we should set them, and obtained the results in the graphs above. Also note that the amount of data preparation needed so that it can be inputted to the network is significantly larger than it was for all the other models.
The final model we'll use to forecast is a type of recurrent neural network (RNN), the long short-term memory (LSTM). The beauty behind LSTMs is in their ability to maintain a memory. While feed-forward neural networks are great for tasks such as image classification, they're limited in their ability to process sequenced data. With no notion of time, feed forward neural networks aren't the best DL models for time series forecasting. RNNs, and LSTMs in specific, do consider the time and order in which data is presented, making them great candidates for time series forecasting.
The architecture we'll use is very basic, and includes:
1. Three LSTM layers with 100 nodes each
2. An output layer and ReLU activation
We also preprocess our data in the same way we did for LGBM, to get our data ready to be used by an LSTM.

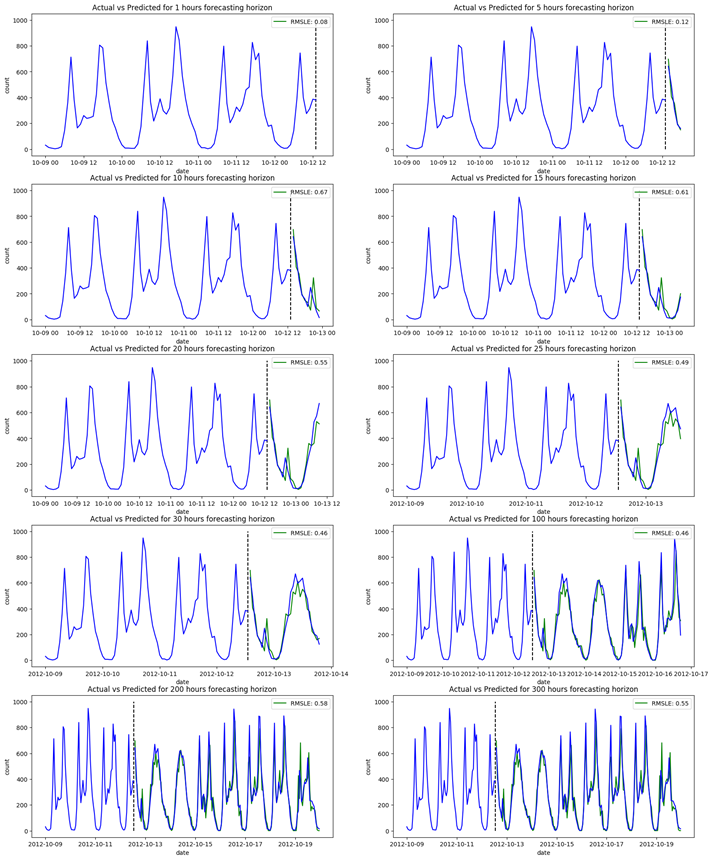
The training time is low, and the LSTM seems to get low forecasting errors for both short- and long-term forecasts. What stands out the most is how our network performs compared to LightGBM. The latter had a much shorter training period, while getting better forecasting results for all time horizons. While the data preprocessing was the same, hyperparameter tuning was much simpler for LightGBM than it was for the LSTM. Whereas the suggestions in LGBM’s documentation worked significantly well, selecting the right architecture, as well as the right number of epochs, batch size and learning rate was a much more difficult task when working with LSTMs, which involved many iterations and lots of trial-and-error.
Conclusion
Now, to answer the question: is deep learning needed for time series forecasting? Of course, Your decision should be based on your business's objectives, resources, and expertise. However, despite the current trend seen in both academia and industry to rely mostly on deep models, they are not always the solution. For the bike sharing demand dataset, we saw that LightGBM outperformed LSTM. While deep models have become easier to create and use, they still come with their fair share of complexity. As your dataset becomes more complicated, so too will your neural network, leading to problems with scalability, explainability and efficiency.
As for the autoregressive models, they were good for short term forecasting, but struggled as we increased the forecasting horizon. More complicated models in SARIMA and SARIMAX came at the cost of a higher training time, with little benefit to the forecasting accuracy. They also involve more parameters, which implies the need for better statistical knowledge. Prophet's training time was significantly better than that of SARIMAX, with similar forecasting results, so it can be used as an alternative to SARIMAX. This doesn't mean, however, that the likes of ARIMA, SARIMA and SARIMAX should be completely ignored. For smaller datasets, that aren't too complex, these autoregressive models can be very useful.
I leave you with the table below, which summarizes the results we got in this article.