Machine learning engineering is a subset of software engineering. Here at Kinaxis’ machine learning team, we consider various types of software architectures when building our forecasting systems to best suit the needs of our customers.
Software architecture is the set of structures needed to reason about a software system and the discipline of creating such structures and systems. Each structure comprises software elements, relations among them, and properties of both elements and relations. Here we design our software to be fast, robust, and scalable by considering different architectural properties in order to meet the different requirements and customer needs. It is an engineering problem that continues to evolve on a daily basis.
Lambda Architecture and supply chain management data
Modern-day supply chain management involves large amounts of customer data, as well as using machine learning algorithms to predict future demand and shipment. Customers want to know their future demand and supply forecasts based on their most recent data and other factors such as holidays. They would like to have these forecasts delivered to them in a timely manner so they can make quick adjustments to their supply chain strategies. This helps the customers stay ahead of the curve and be ready in case of supply chain disruptions. We can design a more robust AI solution to enable this functionality.
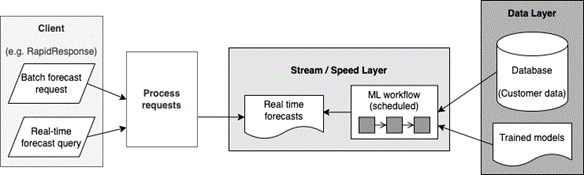
To deal with this, we can use Lambda Architecture. A Lambda Architecture is a way of processing massive quantities of data (i.e., “Big Data”) that provides access to batch-processing and stream-processing methods in a hybrid approach. It consists of a traditional batch processing layer for on-demand jobs (batch requests), and a fast-streaming / speed layer for handling real-time jobs (speed queries). In addition to the batch layer and speed layers, Lambda Architectures also includes a serving layer for responding to user requests (see Fig. 1).
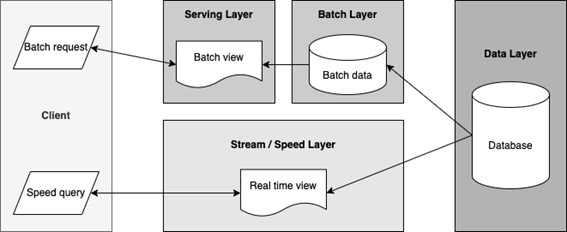
Let’s walk through this together. We begin with a basic scenario. The user wants to get demand or shipment forecasts for a certain date range and a set of items – they request a set of forecasts in the client application (such as the RapidResponse desktop client) and send it to the forecasting server hosted on the cloud, expecting a response containing their requested forecasts.
A basic AI solution for demand forecasting consists of a series of machine learning workflows designed for various purposes such as model training and forecasting, as well as the infrastructure required to process the requests from a client application. But how do they work together?
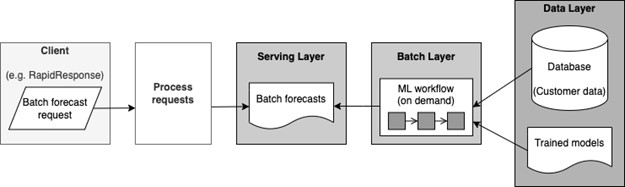
Let’s apply the concept of the batch layer in Lambda Architecture. The user can send a batch request from the client, which triggers a forecasting workflow running on this batch. This batch user request consists of product items and date ranges to forecast for. The forecasting workflow takes the customer data and trained machine learning models that already exist in the data layer to generate the forecasts on the requested items and dates. Once the forecast results are generated, it is passed back to the user on the client.
How to address batch and streaming processing complexities
However, having just a batch serving layer doesn’t cover all the possible use cases. The batch request can be complex (i.e., consists of many items and dates) to create, and the user must wait for the results to compute. Initializing the computing resources for the workflows takes time, and it takes more time for the workflow to run and finish. What if the users just want to see the forecasts for a single item and want the results back quickly? What if they want to see a dashboard of forecasts in real time? It doesn’t make sense for them to create a different batch request each time. They want to be able to see and react to supply chain changes quickly.
This is where we put in the remaining pieces of the puzzle – we can implement a fast-streaming / speed layer for forecasting, let’s call it real-time forecasting. This leverages the full Lambda Architecture. Instead of waiting for a user request to trigger the workflow on-demand, we can achieve near real-time forecasting by running scheduled machine learning forecasting workflows in the background on a frequent basis and save the results in memory.
The user can instead send a query for forecast results on certain date ranges and items, which would get the latest results available and be returned to them right away, instead of waiting for the forecasts to be generated by a workflow in the background. They can even use these live results to build a dashboard that always displays the latest forecasts.
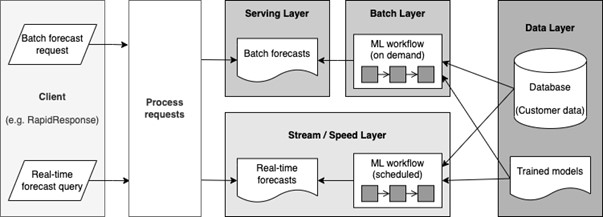
However, with stream processing, some aspects of the batch processing are sacrificed, for instance, the ability to save intermediary results and load them, the ability to spin up different processes to handle different situations and optimizing on memory by forgoing time constraints. Yet, compared to batch processing, stream processing is more memory and CPU-intensive (as more results are held in memory to be accessed quickly, and results always need to be updated / re-computed).
There are some problems with a Lambda Architecture implementation, however. Since there are two separate serving pipelines (batch and streaming), the software has a lot of added complexity. This means duplicating code and infrastructure and having the workflows and data going to two places. There could also be inconsistency between the two pipelines, such as different tech stacks, as well as inconsistent processing of requests and data. It is essentially putting two pieces of software serving two different purposes together into one application.
Is Kappa Architecture the answer?
One way to simplify the architecture is to only have one serving layer, which is the main feature of Kappa Architecture. Kappa Architecture removes the batch processing layer and only keeps the streaming/speed layer. Both batch requests and speed queries from the client will be processed through the speed layer. A batch request will simply be converted to a speed query where the results are simply queried from available data instead of being computed live.
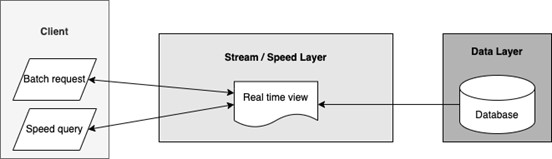
Achieving Kappa Architecture for our machine learning solutions will be less straightforward – we must implement all the components for real-time forecasting, but then remove the infrastructure handling batch requests. Instead, all the batch requests for forecasts will be directed to the real-time forecasting or the speed layer. This way, even the batch requests will have shorter latency compared to before. The forecasts will be automatically refreshed by the machine learning workflow running in the background, based on the latest data instead of being generated at each user request. Any requests will simply query on the available results.
Not only is Kappa Architecture simpler to implement and maintain, but also keeps the processing of our data consistent since there is only one processing pipeline. Although Kappa Architecture is not perfect, it is better when compared to Lambda Architecture; It has all the advantages of Lambda Architecture but not the complexity.
Designing our software and considering software architectural properties are examples of engineering design decisions that we make on a daily basis at Kinaxis. Building the best products using the right architecture helps us best serve our customers' needs and expand our operations to new industries in the future.
References:
Big Data Architectures. Microsoft Learn. (n.d.). https://learn.microsoft.com/en-us/azure/architecture/data-guide/big-data/
Lambda Architecture. Databricks. (n.d.). https://www.databricks.com/glossary/lambda-architecture