
Kinaxis RapidResponse is a powerful and flexible planning platform supported by capabilities such as versioned "what if" scenarios and integrated analytics calculations. Users have the ability to build their own TypeScript-based embedded algorithms on our platform, which can read RapidResponse data and report results in tables and fields. The output can then be accessed directly by the end user or by other RapidResponse processes (such as other algorithms).
To expand what's possible with our platform, we wanted to support reading external data not stored in RapidResponse. Here’s how we did it.
First, we decided on the Parquet file format, which is commonly used by projects in the Hadoop ecosystem for processing large amounts of data. Using a standard format like this makes it easier to integrate with existing systems.
Preliminary support for Parquet files was added to the RapidResponse Data Server itself, as well as the embedded algorithms runtime service. The Apache Arrow C++ library was used for the Data Server, and we chose parquetjs-lite for the embedded algorithms infrastructure (which runs on Node.js). However, we noticed some problems after some initial prototyping.
Drawbacks of JavaScript-based Parquet reading
Using parquetjs-lite made it possible to implement Parquet support in embedded algorithms relatively quickly, but there were several shortcomings. Some were known ahead of time and others only became apparent after developing some test algorithms using the new capability.
1. Maturity. In general, there aren't very many Node.js-based options to read and/or write Parquet files. The Apache Software Foundation's own arrow module doesn't support Parquet files at all. The Node.js modules that do exist aren't well maintained and lack the fine-grained options of Python and C++-based offerings.
2. Duplicated logic. The Parquet implementation in the data server uses some Kinaxis-written helper functions on top of Apache Arrow. Starting from scratch and reimplementing this logic increases maintenance overhead and makes it easy to lose feature parity, which leads to the next point.
3. Compatibility. We found parquetjs-lite failed to load Parquet files written by RapidResponse/Apache Arrow. Parquet files written by other writers could be read successfully, but only if certain settings were used at the time of writing (notably, compression had to be turned off). Under some circumstances, parquetjs-lite would load a file but convert values to the incorrect type (for example, numeric values became strings).
4. Slower performance than expected. We expected to see some slowdown compared to the C++ implementation, but in some cases it took minutes to read a file which the data server could read in seconds.
5. No control over memory usage. Parquet files are partitioned into one or more row groups. Each row group contains a subset of record values for each column in the file, like so:

An entire row group is always loaded into memory at once when iterating records with parquetjs-lite. Because the number of records in a row group can differ from file to file, this can and does result in a significant amount of memory usage when reading large files.
Ideally, we want to be able to specify a fixed number of records to buffer when reading, which is what the data server does using the Apache Arrow C++ library. For more information on the structure of Parquet files, see https://parquet.apache.org/documentation/latest/.
Creating our own module
After evaluating our options, we decided to create our own library to fit our needs. Node.js provides an API for creating C++ modules that can be called from JavaScript code. The API is ABI stable across different Node versions, meaning modules compiled against one version will work with another as long as the major version number is the same.
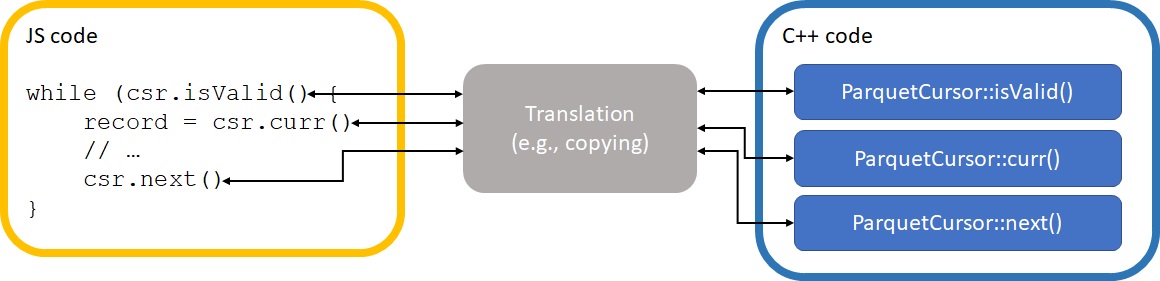
Using this native API, we created a new module for Parquet reading. First, the Kinaxis-written helper functions which wrap Apache Arrow were moved to their own shared library called RRParquet. Next, Node.js bindings for RRParquet were created in the form of the @kinaxis/node-parquet module. The interactions between modules are illustrated below:
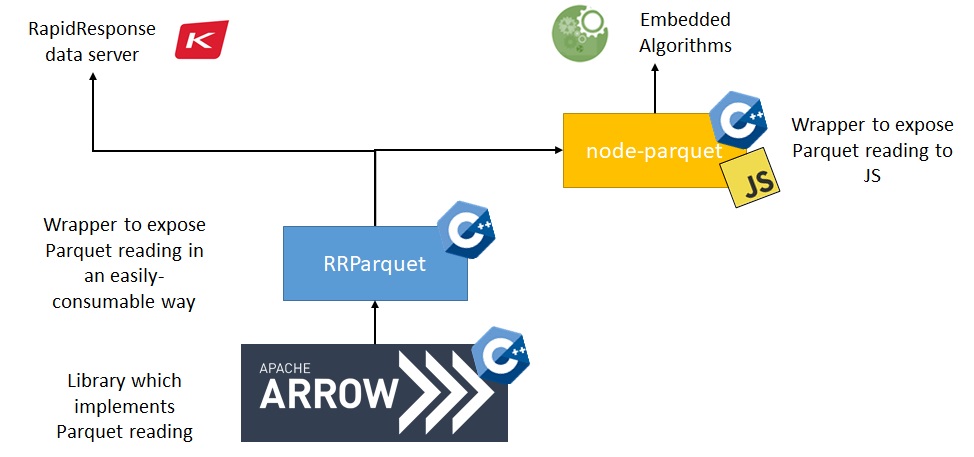
Doing this required some extra time and effort, but before even taking performance into consideration the approach has several benefits:
1. API control. We have full control over the internal logic and public interface of this module. It's been designed to be a (mostly) drop-in replacement for parquetjs-lite, but we aren't limited in any way and can easily add more features as we see fit. It allows us to avoid the headache of fitting a square peg into a round hole.
2. Code re-use. The codebase is easier to maintain and we have feature parity by definition since it is always in sync with the RapidResponse Data Server. Additionally, all teams at Kinaxis who use this library can benefit from collective work that is done.
3. Compatibility. By using the same underlying library as the data server (Apache Arrow), we can be sure that any files written by it are readable by embedded algorithms. We also automatically convert data types that parquetjs-lite does not (e.g., time fields).
4. Constant memory usage. We are now able to limit the number of records loaded at once and as such, memory usage does not balloon uncontrollably with large files. Resource limits are also easy to tune as required.
Performance and some surprises
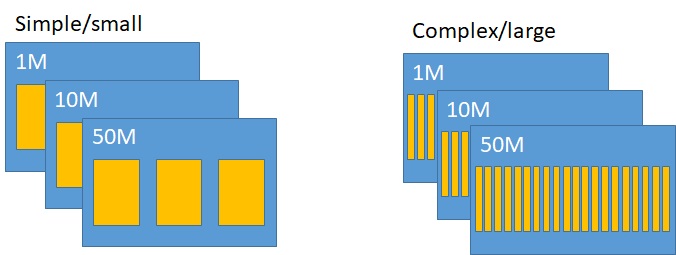
To test performance, two sets of Parquet files were created: simple and complex. The simple files had three numeric (double) columns whereas the complex files had 20 columns of varying types. Three simple and three complex Parquet files containing random data were created with different record counts: one million, 10 million, and 50 million. Both the peak memory usage and iteration time for each file were measured for parquetjs-lite and our new module.
This was done in two modes: accessing all fields and accessing just one field. Because Parquet is a columnar format, only the data that is used will be read from disk, which should show a noticeable difference.
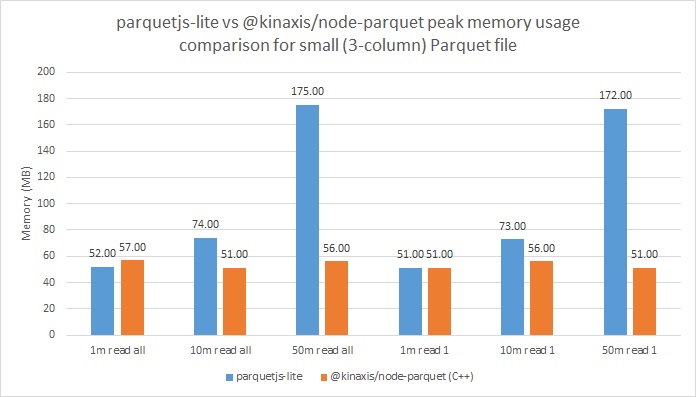
The peak memory usage for simple Parquet files is as expected – with the new module we have much more control over how much memory is used by way of the settings exposed by Apache Arrow. We can see that with our current configuration, memory usage stayed constant around 50-60MB regardless of the number of records that were in the file due to the fixed-size internal record buffer. This is in contrast to parquetjs-lite, which loads an entire row group into memory at once and causes memory usage to grow with file size.
However, when it comes to speed, the results are counterintuitive at first glance. Our new C++ library was actually slower than the previous JavaScript-based one when testing with more than one million records.
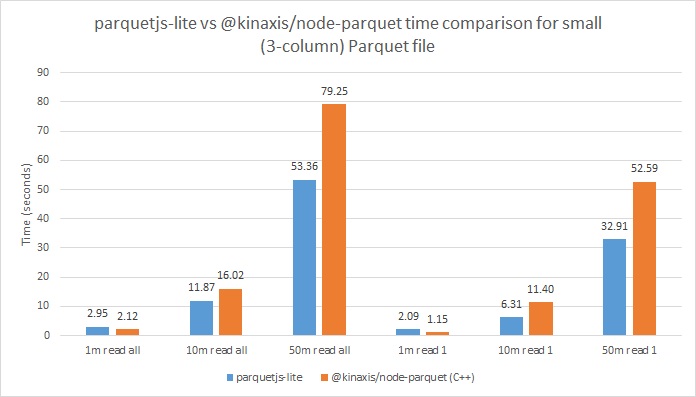
The reason for the slower performance here is because when using a native Node.js module there is overhead associated with switching between the JS and C++ contexts, meaning a cost is incurred every time a function within the library is called. With simple Parquet files like these there isn't enough work done with each call to overcome the inherent cost (even with batch reading), making the JavaScript library faster since it doesn't need to context switch.
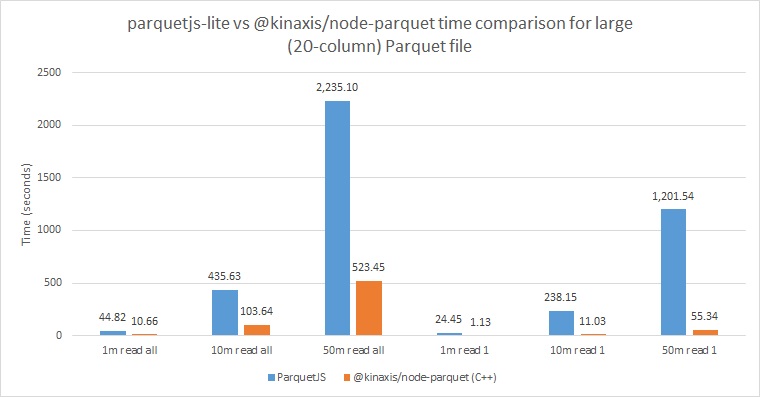
When it comes to the more complex Parquet files, the benefits of our new module can be very clearly seen. Compared to parquetjs-lite, it is ~4x faster when reading all fields and ~21x faster when reading just one field. Additionally, the improvement when reading one field compared to all of them is greater: a ~9x speed increase with the new C++ module compared to ~2x with parquetjs-lite.
These results are explained by the increased complexity of the files. More work is done on each call to the library compared to the simple Parquet files, and so the performance benefits of C++ and Apache Arrow can be seen. Files like these are the typical kind that will be used in production.
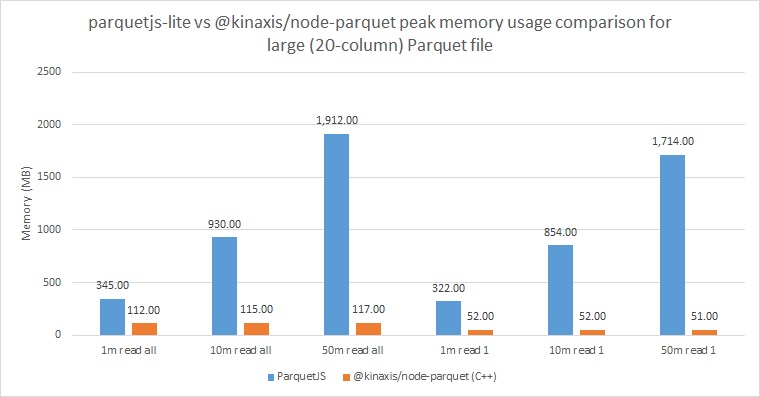
The memory issues of parquetjs-lite are also very visible here. As the number of records increases, the memory usage balloons uncontrollably. Given that we will be running multiple calculations at once, this is unacceptable.
With the new module, regardless of the number of records, the peak memory usage stayed constant around 110-120MB when reading all fields and around 50MB when reading just one field. The peak usage when reading all fields is higher than it was with the simple Parquet files, which makes sense since we are only controlling memory usage by limiting the number of records we load. If records have more data, they will use more memory (albeit not much more as we can see). Again, memory usage settings can be further adjusted if needed since we have full control over this library.
What we learned
While there are many great projects out there, sometimes they don't fit the use case at hand and it's okay to get your hands dirty. Our new C++-based Node.js module offers several benefits compared to parquetjs-lite (the JavaScript-based Parquet reader we used previously). We now have full control over the API, benefit from a time-tested mature library (Apache Arrow), share code and improvements with other teams within Kinaxis, and can constrain memory usage as necessary.
When it comes to speed, there is a tradeoff. Reading less complex Parquet files (with respect to data shape) is slower due to the inherent cost incurred when calling C++ code from JavaScript. However, when reading more complex files the performance gains are significant. It is these more complex files that will be typical in production. Due to this fact and the improved memory usage and maintainability, we believe the tradeoff is justified.
Throughout this process we learned quite a lot of useful information about the Node.js ecosystem and the unexpected ways in which performance can be affected. We also gained valuable insight into effectively sharing code between teams and collaborating on shared libraries consumed by multiple projects. Overall, we consider the endeavor a success.