In a field as deep and complex as supply chain management, it is crucial to foster collaboration between industry and academia. There is a natural symbiosis between the two: Researchers in the academic world are constantly looking for impactful and practical problems to solve while industry searches for new innovations to incorporate into their product offerings. Such partnerships can also help shape student experiences by giving them an opportunity to apply the knowledge they have gained in a more practical setting.
This is especially important to me since I spent most of my career in academia before coming to Kinaxis five years ago as Principal Developer for Algorithms and Business Applications. During my time as a researcher, I was fortunate to benefit from such a partnership through NRC IRAP (National Research Council Industrial Research Assistance Program), and it was critical in helping me bridge the gap from academia to industry. Now, I feel like I have the best of both worlds because I am able to work on extremely complex and interesting supply planning problems and develop algorithms that help to run some of the largest supply chains in the world, all while at a company that values these kinds of partnerships in many ways, from our active intern and co-op program to our Academic Program that seeks to bring our perspective to the classroom.
Forming engaging partnerships
Having had such a positive personal experience with this type of partnership, I was eager to pursue another – this time, from the industry perspective – on behalf of Kinaxis. Early last year, after meeting with my former PhD advisor, Prosenjit Bose from the School of Computer Science at Carleton University, we settled on a line of research that could be quite beneficial to the Kinaxis suite of supply planning algorithms. There are a variety of funding options for such a program from various levels of government. We were particularly attracted to the NSERC Engage program (since discontinued for universities). In exchange for an in-kind contribution from the industry partner, the academic partner would receive up to $25,000 in order to fund the research. In our project, this meant being able to fund three undergraduate researchers (Zoltan Kalnay, Richard St. John, and Alex Trostanovsky).
Solving industry problems
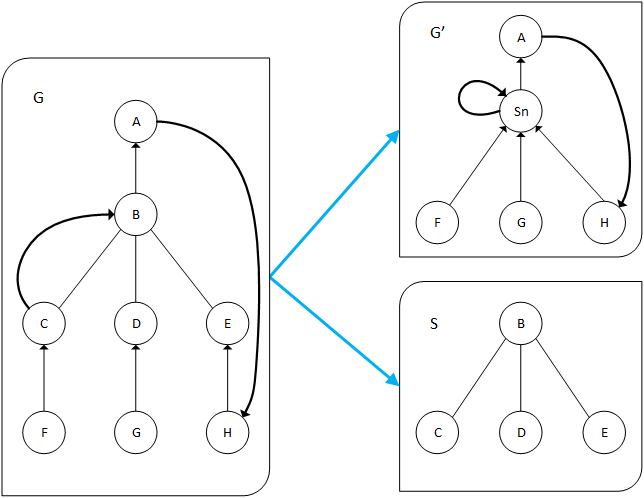 The first line of research was concerned with detecting cycles in product structures. In supply chain management, a product structure is a complete description of how something gets made. For example, to make a bicycle, you need wheels and a frame, and to make a wheel, you need spokes and so on. A common source of data integrity issues is the accidental introduction of cycles in the product structure: To make a bicycle, you need wheels, but to make wheels, you need a bicycle. This is clearly not possible, but such situations can arise with surprising regularity when dealing with “messy” real-world data.
The first line of research was concerned with detecting cycles in product structures. In supply chain management, a product structure is a complete description of how something gets made. For example, to make a bicycle, you need wheels and a frame, and to make a wheel, you need spokes and so on. A common source of data integrity issues is the accidental introduction of cycles in the product structure: To make a bicycle, you need wheels, but to make wheels, you need a bicycle. This is clearly not possible, but such situations can arise with surprising regularity when dealing with “messy” real-world data.
While we are already capable of detecting such configurations, it is notoriously difficult to report them in such a way that they can easily be understood and corrected by planners. Just as importantly, it is critical for such an algorithm to execute quickly on product structures with tens or hundreds of thousands of components. In this image, we see an example of how a larger graph can be decomposed into smaller ones in order to both speed up processing time as well as more concisely describe what cycles look like.
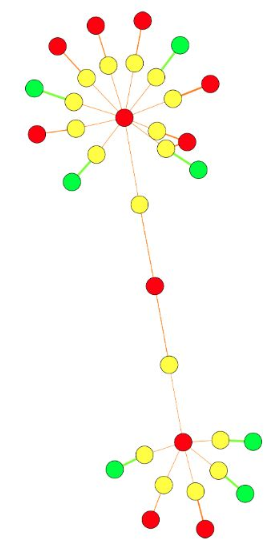 The second line of research was to investigate the ability to automatically detect and propose possible “relaxations” in product structures. Generally speaking, it is faster to calculate a supply plan when product structures are small and self-contained. Intuitively, the manufacturing process for a bicycle would likely be rather distinct from the process for a bottle of shampoo, and so they can likely be planned at the same time. By planning them concurrently (and taking advantage of parallel processing), we are able to gain significant savings on the cost of calculating the plan. Conversely, the assembly of a bicycle might “interfere” with the assembly of other models of bicycles because they must compete for time on the same assembly line.
The second line of research was to investigate the ability to automatically detect and propose possible “relaxations” in product structures. Generally speaking, it is faster to calculate a supply plan when product structures are small and self-contained. Intuitively, the manufacturing process for a bicycle would likely be rather distinct from the process for a bottle of shampoo, and so they can likely be planned at the same time. By planning them concurrently (and taking advantage of parallel processing), we are able to gain significant savings on the cost of calculating the plan. Conversely, the assembly of a bicycle might “interfere” with the assembly of other models of bicycles because they must compete for time on the same assembly line.
In some situations, planners overestimate the extent of this interference and force components to be planned together when perhaps in practice they do not interfere with one another. For example, if we have much more capacity than we could possibly use, it does not really matter if the schedules interfere with each other. The research team worked to devise methods that could identify such situations and propose “harmless” simplifications to the product structure that could drastically improve the performance of generating the plan. Of course, for this simplification to be helpful, it must be calculated quickly. In this image, we see how rearranging the product structure and coloring similar to a heat map, the possible candidates for removal become much more apparent. Here, the removal of the red node in the center would separate the product structure into two much smaller structures and result in significantly less computation time.
Going from research to implementation
Our six month research project recently concluded with a presentation to various interested parties and was met with excitement about future possible collaborations. We are now evaluating how this research can be incorporated into our solutions. I was thrilled with the progress that the team made, and it certainly exceeded my expectations, especially on our first such venture. I’m looking forward to our next!
