
One of the most important drivers of revenue in retail are replenishable products, such as drinks and personal hygiene products. Their importance can be explained and summarized succinctly with this quote:
Toilet paper isn’t glamorous but it ships by the boatload.
These staples are one of the primary factors driving store sales on a long-term basis. Modelling the quantities sold for these high-volume products on an aggregate level has been well explored by Poisson processes and Auto-Regressive models. Demand forecasting at the chain or store-level is certainly useful in planning sales and inventory, but marketing and promotional mechanisms operate on a much more granular level. Individual customers have diverse needs and tastes which can be difficult to predict. However, sparse transactions on the individual customer level make predicting purchase times per-SKU prohibitively difficult.
We attempted to solve this problem in our published work, “Multivariate Arrival Times Recurrent Neural Network” (MATRNN). With MATRNN, we address this by combining recurrent neural networks with survival modelling to make use of partially-observed information regarding arrival times. You can read more about this model in the Rubikloud repository and we presented it at the International Conference on Data Mining 2018 DMS Workshop.
Inspiration from survival modelling
Modelling time-of-death is important in healthcare, which is made difficult by the sparsity of fully-observed data points. A common approach is to utilize the age of a patient to model the time-of-death. Instead of predicting the actual time-of-death, we instead find a distribution that best explains the event that the patient’s time-of-death exceeds his current age, which is termed the “maximum likelihood” approach.
The hazard rate is the instantaneous death rate and is given by λ(t)=S′(t)/S(t), where S(t)=P(T>t) where T is the time-of-death. In survival modelling, the assumption is that the hazard rate for every individual is related to a common base hazard rate. We then find the maximum likelihood estimates by using optimization techniques. This tweak allows healthcare professionals to better assess the impact of their interventions on prolonging the lifetimes of their patients.
A distributional approach to arrival times
In a similar approach, we will predict the distribution of the remaining time until the next purchase made by a customer for a particular product instead of the actual time. Since we would like to predict jointly for multiple products as well as repeated purchases, it would be useful to have a general model for predicting multiple arrival times.
Our approach directly outputs the distributional parameters for the arrival times instead of modelling them through the hazard rate function. These parameters are the output of a Recurrent Neural Network (RNN), wherein at each time step t, the RNN outputs the parameters θ.
The assumption here is that the distribution of time remaining until next purchase (denoted by the random variable T) is defined by P(T≤s)=F(s,θ), where F(⋅,⋅) is a member of a pre-defined class of distributions parametrized by θ.
Likelihood/loss function
Under these assumptions, we can compute the likelihood at time t directly, given that time st has passed since the previous purchase.
If remaining time to next purchase is yt, the likelihood at this time is:
P(T = yt | T > st, θt)
If we do not observe the next purchase by the end of the training period τ, the likelihood is instead:
P(T > τ − t | T > st, θt)
Putting it together
Recurrent Neural Network with memory states ht take covariates Xt and returns θt, the distribution for time to next purchase T. The loss function is the negative log-likelihood.
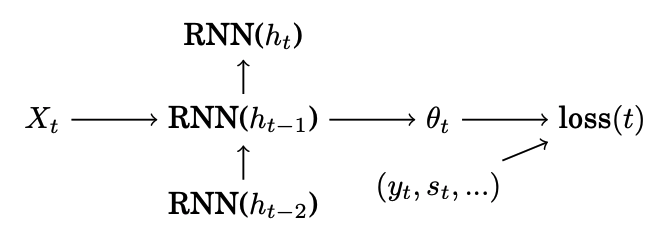
Since we are predicting the distribution of the time-to-purchase instead of the actual value, we maximize the likelihood to find the parameters of that distribution which best explains the observed data.
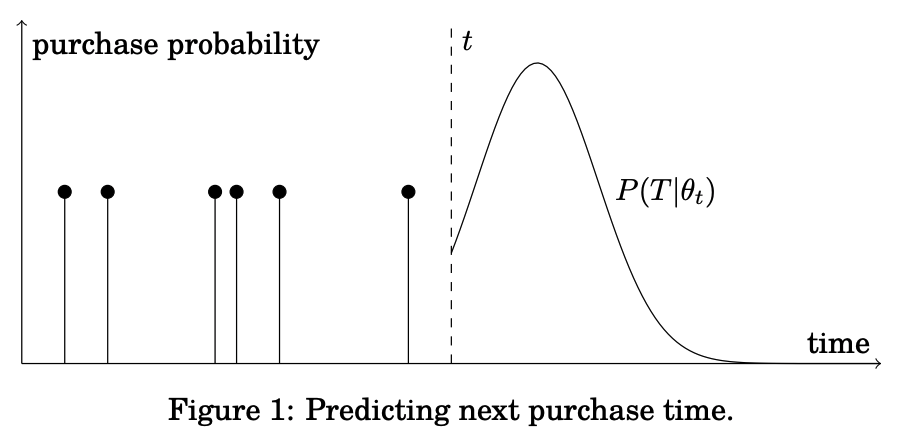
Testing on engine failure data
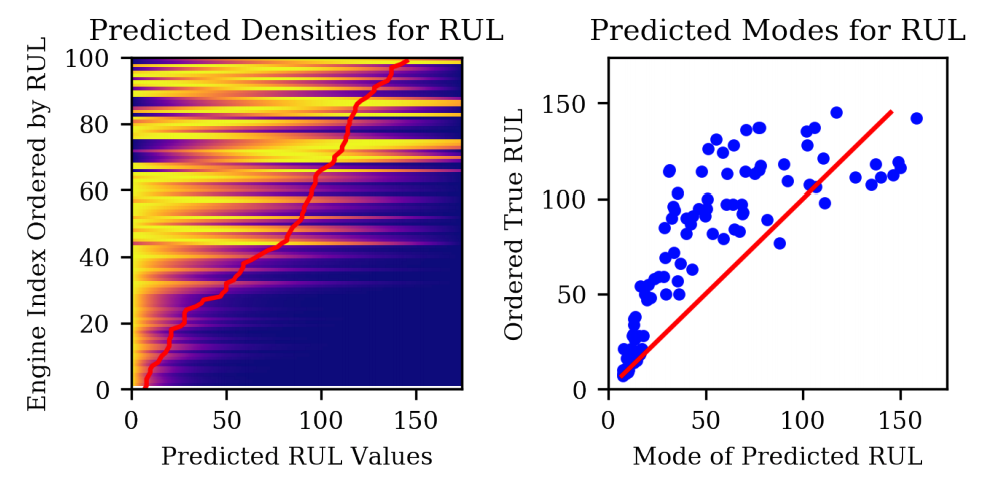
We ran the model on a high-dimensional dataset to predict engine lifetimes available here. The implementation is also available in our repository.
In the training dataset, the engine is run until failure while in the testing dataset, data is collected until some time before failure. Our approach achieves good results and it can be observed that the predicted densities line up with actual Remaining Useful Lifetimes (RUL).
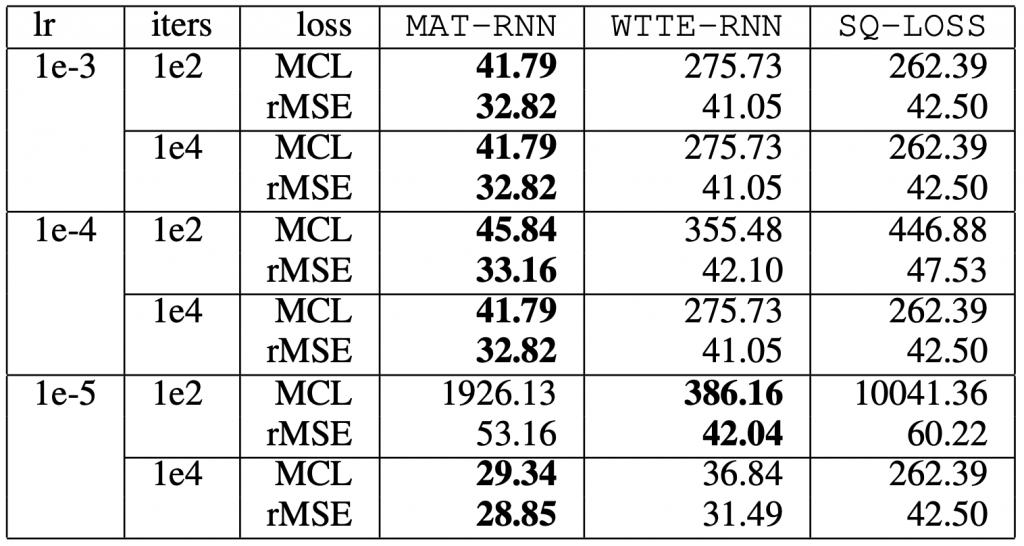
Here’s a table of testing losses comparing our model MATRNN against a similar likelihood-based arrival time model WTTE-RNN as well as a recurrent neural network with a regular squared-loss SQRNN. MCL is a custom loss function used by a PHM competition based on the same CMAPSS dataset that more heavily penalizes over-estimation of RUL. We find that we’re able to achieve good results with minimal hyper-parameter searching.
Individual retail purchases
We also ran our model on a few categories/baskets of products. We also included some metrics of the mean number of purchases (μ) as well as the proportion of customers who purchased other products in basked (p).
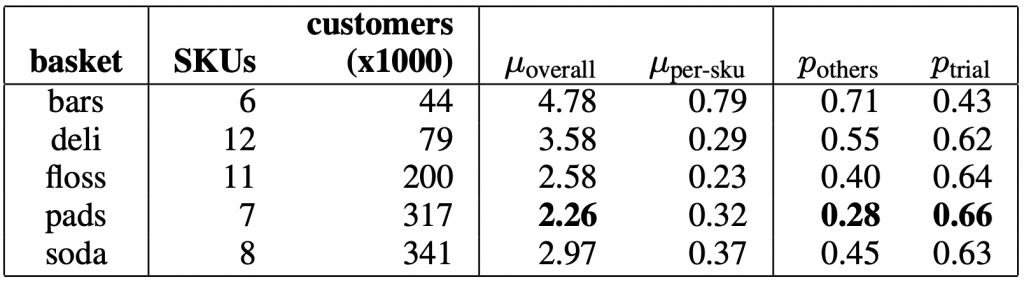
For each category, we predict the purchase times jointly of a few popular products for every individual who purchased any of the products during training. We compared our approach to other state-of-the-art prediction methods such as Random Forests and Recurrent Neural Networks with Mean-Squared-Error (MSE) loss. Accuracy is measured in terms of whether the customer purchases the product during the testing period.
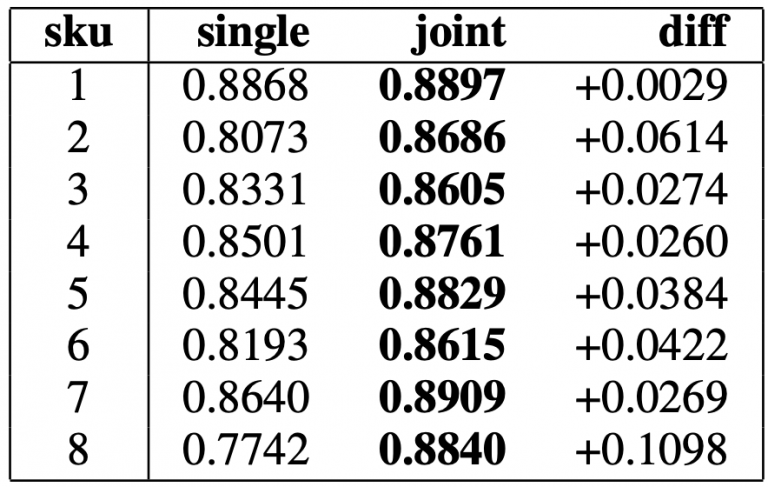
We find that our model outperforms both the Random Forest model as well as RNN with the usual MSE loss in the summary table of classification metrics. We were able to show empirically the benefits of training the model jointly as we find that fitting a different MATRNN model for every single product yields worse results than a smaller model that is trained jointly over multiple products.
Learn more
Our implementation is available with a notebook to replicate the Engine failure experiment here. Our paper, “Multivariate Arrival Times Recurrent Neural Network” was presented at the International Conference on Data Mining 2018 DMS Workshop and is also available on Arxiv.
Editor's note: This blog is part of a series originally published on Rubikloud's blog, "kernel." Kinaxis acquired Rubikloud in 2020. For more information about our Retail and AI capabilities, click here.



