

Robi Khan is Vice President, Supply Chain Solutions at Kinaxis. He is an experienced developer, architect, and manager on a variety of software projects spanning three decades.
Much of today's conversation around artificial intelligence is focused on the experiences users interact with directly—LLM chat, copilots, and AI agents that help people work faster. At Kinaxis, we're also exploring another side of AI: using it to help our engineers build better software.
As part of Google DeepMind's AlphaEvolve Early Access Program, Kinaxis researchers have been evaluating how evolutionary AI can improve the sophisticated forecasting and optimization algorithms that underpin our supply chain orchestration platform.
Rather than replacing engineers or rewriting our software, AlphaEvolve helps our teams explore new ways to improve mature algorithms that have already been refined over many years. Given an existing algorithm, clear evaluation criteria, and rigorous validation, it can generate, test, and refine thousands of potential improvements—helping our engineering teams discover optimizations faster than traditional development alone.
Why does that matter?
While much of the industry is focused on customer-facing AI experiences, we're also investing in AI behind the scenes to continuously improve the technology that powers supply chain orchestration. Every improvement to forecasting, optimization, and decision-making algorithms has the potential to help customers respond faster to disruption, evaluate more scenarios, and make better decisions—without changing how they interact with the platform.
The work highlighted here represents early research rather than production capabilities, but the initial results are encouraging. In just a few weeks, AlphaEvolve helped our researchers identify measurable improvements across both optimization and demand forecasting, demonstrating how emerging AI technologies can accelerate software innovation while keeping human expertise firmly in control.
The following sections explore two examples of how our Operations Research and Machine Learning teams used AlphaEvolve to improve mature algorithms, what we learned, and why this research is exciting for the future of supply chain orchestration.
Using AlphaEvolve to improve supply chain optimization
Supply chain planning depends on solving large, complex Mixed-Integer Linear Programming (MILP) optimization models quickly enough for people to act on the results. The challenge isn't simply to make the solver run faster, it's to reduce computational effort while preserving the quality of the plan. Even small improvements can matter when similar models are solved repeatedly across planning workflows.
At Kinaxis, we used AlphaEvolve to explore one focused optimization problem: how to simplify a large planning model before the final solve without materially degrading solution quality. We started with a working human-designed heuristic, a clear evaluation setup, and our own quality checks. AlphaEvolve’s role was to search for stronger decision logic within those boundaries—not to replace our solver, engineering judgment, or validation process.
The original seed heuristic and the evolved heuristic both use the same overall solve pattern: solve an LP relaxation iteratively, use LP results to decide which integer variables can be removed, update the LP after removals, and finally solve a reduced MILP with Gurobi.
The difference is inside the variable-removal logic. The original seed heuristic uses a simple fixed-threshold rule. The evolved heuristic changes that into an adaptive, ranked selection process. It collects possible variables, scores them using LP value and objective coefficients, sorts them, and removes only the highest-priority candidates within a per-round cap.
On a representative test instance, the evolved heuristic achieved lower runtime and less solver work, removed more candidate variables, and had a slightly smaller objective gap than the original seed heuristic.
Use case context
Topic | Explanation |
Use case | Remove selected integer variables before solving a reduced/smaller MILP. |
Goal | Reduce solver work and runtime without losing objective quality. |
Approach | Start from the original seed heuristic and use AlphaEvolve to explore improvements to the removal logic. |
Evaluation | Compare the Full MILP baseline, original seed heuristic, and evolved heuristic. |
The central question is what AlphaEvolve changed in the logic that chooses which integer variables are removed before the reduced MILP solve.
What both heuristics are trying to do
Both the original seed heuristic and the evolved heuristic follow the same outer solve strategy. AlphaEvolve was configured to operate within boundaries that preserved the solver-related phases and the reduced-MILP approach. It explored the decision rules used to choose which variables are removed.
Step | Action | Plain-English meaning |
1 | Solve LP relaxation | Temporarily relax integer restrictions to get a faster continuous approximation. |
2 | Choose variables to remove | Use the LP solution as a guide for reducing the model before the MILP solve. |
3 | Re-solve after removals | Update the LP after each round so later decisions use a fresh LP solution. |
4 | Solve reduced MILP | Let Gurobi solve the smaller MILP and compare against the full baseline. |
Original seed heuristic
The seed method is intentionally simple. Each round, it solves the LP relaxation and then reviews the LP variables one at a time. For every integer variable, it checks one condition: is its optimal LP value above a fixed threshold? If the answer is yes, the variable is marked for removal from the next LP, not the MILP. After all variables have been reviewed, the LP is solved again and the process repeats. Variables removed during the iterative LP screening rounds are excluded only from subsequent LP relaxations. Before constructing the final reduced MILP, those variables are restored to the model; the final reduction is determined using the remaining candidate set in the final LP iteration.
Risk: The approach is blunt: it treats all above-threshold integer variables as equally removable, even though their objective impact may differ.
Evolved heuristic
The evolved heuristic changes the removal decision from immediate deletion to ranked selection. It no longer removes a variable only because it passes a threshold. Instead, it first identifies possible candidates, scores them, ranks them, and then removes only the highest-priority candidates allowed by the round limit.
Area | What changed |
Setup before the loop | Use an adaptive threshold and a removal cap that are adjusted across rounds; measure the scale of each candidate’s objective coefficient. |
New loop structure | First collect possible variables to remove and track each candidate’s LP value and objective coefficient. If no candidates exist, stop. Then compute a priority score for each candidate. |
New removal policy | Sort candidates by priority score, remove the highest-ranked candidates first up to the current round limit, then re-solve the LP and repeat. |
The main change is therefore a shift from “if the LP value is above the threshold, remove now” to “identify candidates, evaluate them together, rank them, and remove only the best candidates allowed in this round.”
Code-level changes in the evolved algorithm
Setup and parameter changes
Line of logic | Original seed | Evolved heuristic | Change |
LP value threshold | Fixed threshold | Adaptive threshold adjusted across rounds | Changed |
Minimum threshold | Not present | Safeguard floor | New |
Max LP re-solves | Fixed round limit | Fixed round limit | Same |
Max removals per round | Not present | Adaptive cap adjusted across rounds | New |
Minimum removal cap | Not present | Safeguard floor | New |
Objective coefficient scale | Not used | Pre-loop calculation across candidate variables | New |
The seed has one main knob: a fixed LP value threshold. The evolved heuristic separates two ideas: how easily a variable becomes a candidate, and how many candidates can actually be removed in a round.
Inside the main loop
Loop | Plain-English behavior |
Original seed loop | Go through LP variables one by one; check whether the variable is integer; check whether its LP value is above a fixed threshold; if both are true, mark it for removal; count removals and re-solve the LP. |
Evolved loop | Compute the current threshold and removal cap; collect candidates with LP value and objective coefficient; score candidates; sort candidates; remove only the top candidates up to the cap; re-solve the LP. |
The evolved method changes the decision process, not only the parameter values. The outer loop is still recognizable, but the action inside the loop is more structured and more cautious.
How the evolved version decides what is safer to remove
The evolved heuristic computes a priority score using two signals: LP value and objective impact.
Signal | Meaning |
Signal 1: LP value | A smaller LP value is treated as safer to remove. Values are normalized within the current candidate group, so the rule adapts to the current round. |
Signal 2: objective impact | Larger positive objective coefficients are easier to remove than smaller or zero objective coefficients. Large negative objective coefficients are protected because removing those variables may hurt the objective more. |
Final action | Combine the two signals into a priority score, sort candidates by that score, and remove only the top-ranked candidates allowed by the round cap. |
Measured results
The evolved heuristic reduced runtime and solver work while keeping objective quality close to the Full MILP baseline.
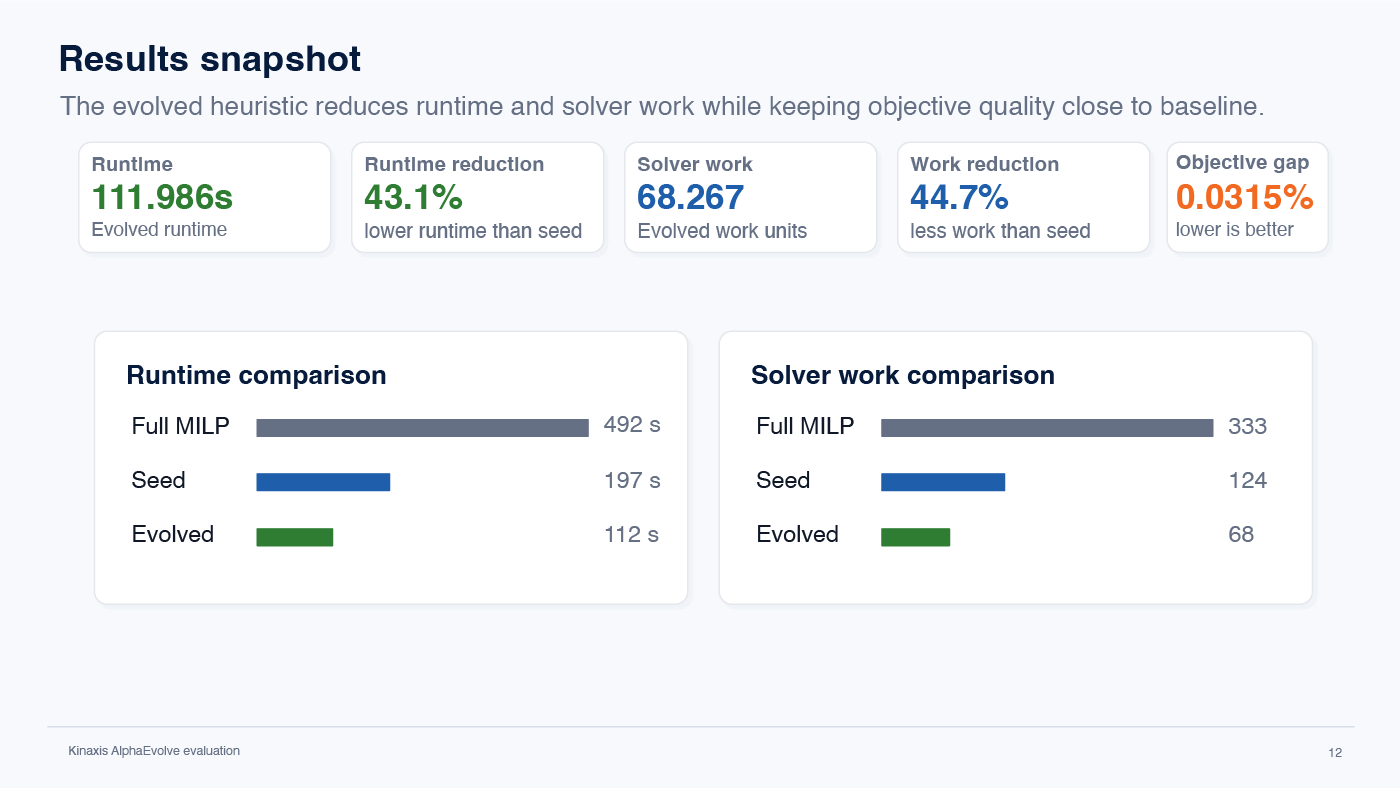

The evolved version removed more candidate variables, which contributed to lower runtime. The candidate ranking and per-round cap help balance model reduction and objective quality.
Business impact
Organizations managing complex supply chains depend on optimization algorithms that produce high-quality plans quickly enough to respond to constant change. Even modest improvements in optimization performance can translate into faster planning cycles, more scenarios evaluated and better decisions.
Kinaxis engineers have spent years refining the optimization capabilities behind our platform. AlphaEvolve allowed us to build on that work by exploring new approaches significantly faster than traditional development alone.
Our early testing demonstrated optimization logic that delivered nearly 5x faster performance than a naïve mathematical solve and approximately 2x faster performance than our existing human-developed tuning approach, while maintaining planning quality.
These results are still being validated, but they demonstrate how AI-assisted software development can help accelerate innovation behind supply chain orchestration.
Demand forecasting: Improving forecast accuracy and runtime with AlphaEvolve
Demand-forecasting workflows have to balance three pressures at once: predictive accuracy, computational efficiency, and implementation simplicity. A model that lowers error but doubles runtime makes iteration painful; a fast pipeline that drifts on accuracy erodes trust in downstream planning. The hard part is improving one dimension without quietly degrading the other.
These workflows are also governed by many engineering choices: how features are built, how lag values are propagated across the horizon, which model family is used, and how categorical signals are encoded. Each choice has an accuracy effect and a runtime effect, and the two effects rarely move in the same direction.
This project applied AlphaEvolve to a focused forecasting benchmark with an expert-led baseline program and an evaluation harness that measured accuracy and runtime on both a validation split and a blind test split. AlphaEvolve's role was to search for stronger forecasting logic inside those boundaries. The evolved program improved every tracked metric on validation and kept meaningful gains on the blind test split, with forecast error reduced by up to 22.6% and runtime reduced by 90.5%.
What forecast accuracy and runtime tell us
For planning teams, forecast accuracy is the headline metric: it determines whether the demand signal feeding inventory, capacity, and replenishment decisions can be trusted. WMAPE, MAE, and RMSE capture complementary views of that signal.
- WMAPE summarizes percentage error weighted by the volume of the demand and is the headline score on the benchmark.
- MAE reports the average absolute error in the same units as the data.
- RMSE penalizes large misses more strongly, which makes it sensitive to outlier weeks and demand spikes.
Runtime is the second axis. A pipeline that runs in seconds rather than minutes supports more frequent re-training, more thorough hyperparameter sweeps, and more responsive what-if analysis. Runtime gains are not cosmetic; they change how often a forecasting workflow can be exercised and how confidently teams can iterate on it.
A useful evolved program therefore has to move both axes at once and has to do so on a blind test split that AlphaEvolve never sees during search. That last condition is what separates a real improvement from a validation-only artifact.
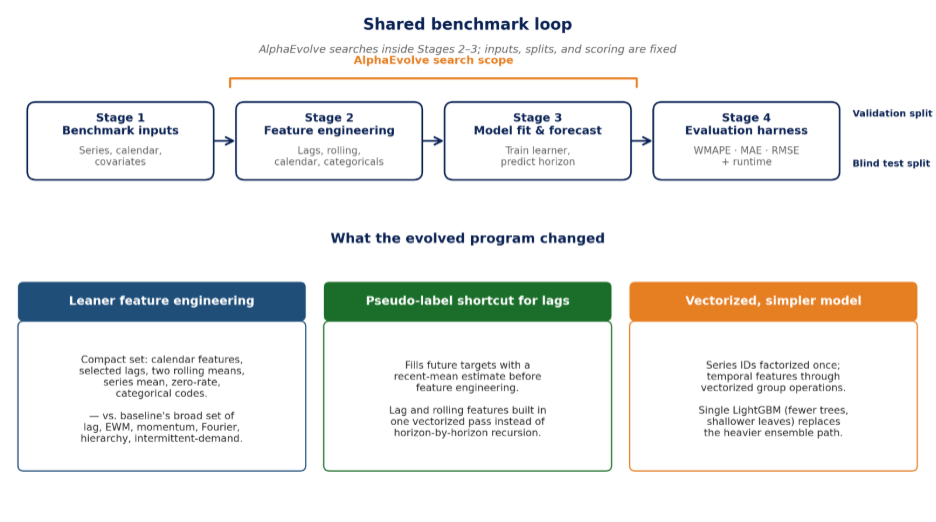
What the baseline already did—and why AlphaEvolve helped
The baseline program was already a sensible forecasting pipeline. It built a broad set of engineered features, fit an ensemble-style model, and produced forecasts that the evaluation harness could score. It gave us a stable reference for both forecast quality and runtime — exactly the kind of working starting point AlphaEvolve needs.
Manual tuning mostly adjusted hyperparameters and feature settings around the same overall design: heavy feature engineering (lags, rolling stats, EWM, Fourier seasonality, hierarchy aggregations, intermittent-demand signals), recursive lag propagation across the horizon, and a richer model configuration. AlphaEvolve gave us a broader way to search across feature construction, lag handling, grouping strategy, and model complexity.
How we measured progress
A stronger candidate had to improve more than a single accuracy metric. The optimization objective combined forecast accuracy and execution speed in fixed proportions. MAE and RMSE were tracked as supporting diagnostics, and the blind test split was held out from AlphaEvolve entirely to test whether validation gains would generalize.
| Component | Weight | Role in the objective |
| WMAPE | 80% | Primary accuracy signal; with errors weighted proportionally by the volume of the demand |
| Runtime | 20% | Efficiency signal; lower runtime rewards faster programs when accuracy is comparable. |
Baseline vs. leading evolved candidate
The leading evolved program changed the internal logic in three important ways. It built a leaner feature set, replaced recursive lag propagation with a vectorized pseudo-label shortcut, and replaced the heavier ensemble path with a single, lighter LightGBM model.
The three core improvements
| Leaner feature engineering | Pseudo-label shortcut for lags | Vectorized, simpler model |
| Replaces the baseline's broad set of lag, rolling, EWM, momentum, Fourier-seasonality, hierarchy, and intermittent-demand features with a compact set: calendar features, selected lags, two rolling means, series mean, zero-rate, categorical codes, and available numeric signals. Cuts memory use, feature-construction time, and downstream training cost. | Fills future target values with a fast recent-mean estimate before feature engineering. This lets short-term lags and rolling means be built in a single vectorized pass instead of a horizon-by-horizon recursive prediction loop, while still preserving useful temporal structure. | Factorizes series IDs once and runs most temporal features through vectorized group operations. A single LightGBM model with fewer trees and shallower leaves replaces the baseline's heavier ensemble path, preserving useful nonlinear capacity while shortening training time. |
Results
On the blind test split, the evolved program lowered WMAPE from 0.5024 to 0.4563 (9.2% lower) and RMSE from 11.6225 to 8.9938 (22.6% lower), while cutting runtime from 15.87 s to 1.50 s (90.5% lower). Every tracked metric moved in the right direction on both splits.
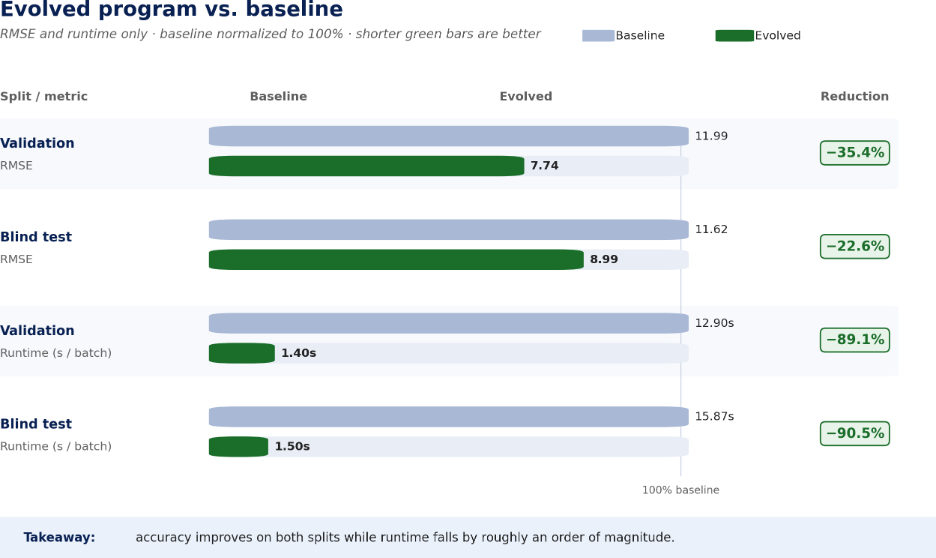
Blind test split details
| Program | WMAPE | MAE | RMSE | Time (s) / batch |
| Baseline | 0.5024 | 4.3971 | 11.6225 | 15.87 |
| Evolved | 0.4563 | 3.9932 | 8.9938 | 1.50 |
The validation result shows that AlphaEvolve found stronger implementations given one dataset, and the blind dataset result confirms that the improvement was not an artifact of the iterative process but a generalizable program.
Claim boundaries and next steps
The evolved program is the current winner on this benchmark, not a universal production guarantee. The blind test split gives us confidence that the gains are not specific to the validation tuning, but a single benchmark is still limited.
Next, we should evaluate the evolved program across a wider set of demand datasets drawn from multiple industries, with different seasonality patterns, intermittency profiles, hierarchy depths, and horizon lengths.
The main success is not only the evolved program itself.
The broader win is a repeatable, governed process for improving forecasting code, where we can speed up experimentation in crucial implementation areas and use human review to decide what is safe to promote.
Business impact on forecasting
Demand forecasting is foundational to effective supply chain orchestration. Better forecasts improve downstream decisions across inventory, production, workforce planning and customer service.
Using AlphaEvolve, our Machine Learning team evolved an already highly optimized forecasting algorithm against benchmark datasets. The resulting implementation not only improved forecast quality but reduced runtime by approximately 10x, allowing our teams to experiment faster and evaluate more approaches in less time.
While additional validation across broader datasets is still required, these early results demonstrate how AI-assisted software development can accelerate innovation while maintaining the rigorous engineering standards enterprise software demands.
Looking ahead
AI is changing more than how people interact with software. It's also changing how enterprise software is designed, tested and continuously improved.
At Kinaxis, we're exploring both.
Our participation in Google DeepMind's AlphaEvolve Early Access Program reflects our broader commitment to evaluating emerging AI technologies that can improve the forecasting, optimization and decision-making capabilities that underpin supply chain orchestration.
While this work remains in the research stage, it demonstrates how AI can help our engineering teams innovate faster while maintaining the quality, trust, and human oversight our customers expect. As we continue validating these approaches across broader datasets and real-world scenarios, we're excited about the opportunity to translate these learnings into future innovations for the world's most complex supply chains.
Acknowledgements
This work represents a collaborative effort across Kinaxis' Supply Planning Science, Operations Research and Machine Learning teams.
Special thanks to:
- Vahid Eghbal, Senior Software Developer, Operations Research, for leading the optimization research and technical content featured in this article.
- Sebastien Ouellet, Senior Staff Software Developer, Machine Learning, for leading the demand forecasting research and technical content featured in this article.
We would also like to thank the following contributors at Kinaxis for their support and collaboration throughout this project:
- Yankai Zhang
- Yaroslav Salii
- Christopher Wang
- Marc Olivier-Doyon
- Femi Ajayi
- Jeff Beaulieu
We also extend our thanks to the Google Cloud and Google DeepMind teams for their partnership and support throughout the AlphaEvolve Early Access Program:
- Anant Nawalgaria
- Skander Hannachi
- Adrian Jones
- Mark Schadler
- Saurabh Pandey
- Chris Lileikis